Photo from wikipedia
This paper proposes a novel method of optimizing locomotion controller for virtual characters, which is constructed with the deep neural network and learned with the assistance of existing motion data.… Click to show full abstract
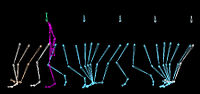
This paper proposes a novel method of optimizing locomotion controller for virtual characters, which is constructed with the deep neural network and learned with the assistance of existing motion data. The learning is accomplished with a progressive reward function by starting from a simple reward function and gradually imposing advanced requirements on the gait pattern. A multi-critic model is proposed to address the dynamically changing reward function by evaluating the individual goal in a separate fashion. This strategy proves effective in avoiding the local minima that are likely to occur when a set of weighted reward functions are introduced at the beginning of the optimization. The results show that the integration of motion data not only ensures the consistency between the synthetic and original motions but also accelerates the learning of network parameters. We demonstrate the application of our method to a variety of virtual characters (cheetah, hopper, 2-D walker, and 3-D humanoid) performing various tasks (walking, running, jumping, and traversing at different velocities and across uneven terrains).
Journal Title: IEEE Access
Year Published: 2018
Link to full text (if available)
Share on Social Media: Sign Up to like & get
recommendations!