Photo from wikipedia
Recent studies in Learning to Rank have shown the possibility to effectively distill a neural network from an ensemble of regression trees. This result leads neural networks to become a… Click to show full abstract
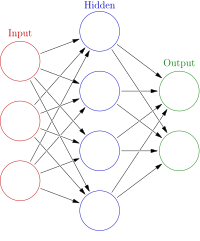
Recent studies in Learning to Rank have shown the possibility to effectively distill a neural network from an ensemble of regression trees. This result leads neural networks to become a natural competitor of tree-based ensembles on the ranking task. Nevertheless, ensembles of regression trees outperform neural models both in terms of efficiency and effectiveness, particularly when scoring on CPU. In this paper, we propose an approach for speeding up neural scoring time by applying a combination of Distillation, Pruning and Fast Matrix multiplication. We employ knowledge distillation to learn shallow neural networks from an ensemble of regression trees. Then, we exploit an efficiency-oriented pruning technique that performs a sparsification of the most computationally-intensive layers of the neural network that is then scored with optimized sparse matrix multiplication. Moreover, by studying both dense and sparse high performance matrix multiplication, we develop a scoring time prediction model which helps in devising neural network architectures that match the desired efficiency requirements. Comprehensive experiments on two public learning-to-rank datasets show that neural networks produced with our novel approach are competitive at any point of the effectiveness-efficiency trade-off when compared with tree-based ensembles, providing up to 4x scoring time speed-up without affecting the ranking quality.
Journal Title: IEEE Transactions on Knowledge and Data Engineering
Year Published: 2022
Link to full text (if available)
Share on Social Media: Sign Up to like & get
recommendations!