Photo from wikipedia
There are two significant problems associated with predicting protein-protein interactions using the sequences of amino acids. The first problem is representing each sequence as a feature vector, and the second… Click to show full abstract
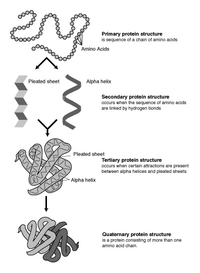
There are two significant problems associated with predicting protein-protein interactions using the sequences of amino acids. The first problem is representing each sequence as a feature vector, and the second is designing a model that can identify the protein interactions. Thus, effective feature extraction methods can lead to improved model performance. In this study, we used two types of feature extraction methods—global encoding and pseudo-substitution matrix representation (PseudoSMR)—to represent the sequences of amino acids in human proteins and Human Immunodeficiency Virus type 1 (HIV-1) to address the classification problem of predicting protein-protein interactions. We also compared principal component analysis (PCA) with independent principal component analysis (IPCA) as methods for transforming Rotation Forest. The results show that using global encoding and PseudoSMR as a feature extraction method successfully represents the amino acid sequence for the Rotation Forest classifier with PCA or with IPCA. This can be seen from the comparison of the results of evaluation metrics, which were >73% across the six different parameters. The accuracy of both methods was >74%. The results for the other model performance criteria, such as sensitivity, specificity, precision, and F1-score, were all >73%. The data used in this study can be accessed using the following link: https://www.dsc.ui.ac.id/research/amino-acid-pred/. Both global encoding and PseudoSMR can successfully represent the sequences of amino acids. Rotation Forest (PCA) performed better than Rotation Forest (IPCA) in terms of predicting protein-protein interactions between HIV-1 and human proteins. Both the Rotation Forest (PCA) classifier and the Rotation Forest IPCA classifier performed better than other classifiers, such as Gradient Boosting, K-Nearest Neighbor, Logistic Regression, Random Forest, and Support Vector Machine (SVM). Rotation Forest (PCA) and Rotation Forest (IPCA) have accuracy, sensitivity, specificity, precision, and F1-score values >70% while the other classifiers have values <70%.
Journal Title: BMC Genomics
Year Published: 2019
Link to full text (if available)
Share on Social Media: Sign Up to like & get
recommendations!